The Problem
ETVWin is a Telugu streaming platform. Growing up in the 90s, ETV was the only source of entertainment for many Telugu households. It was a cultural phenomenon. So I thought, they have a huge library of nostalgia inducing content. But there is one problem - their site search sucks!
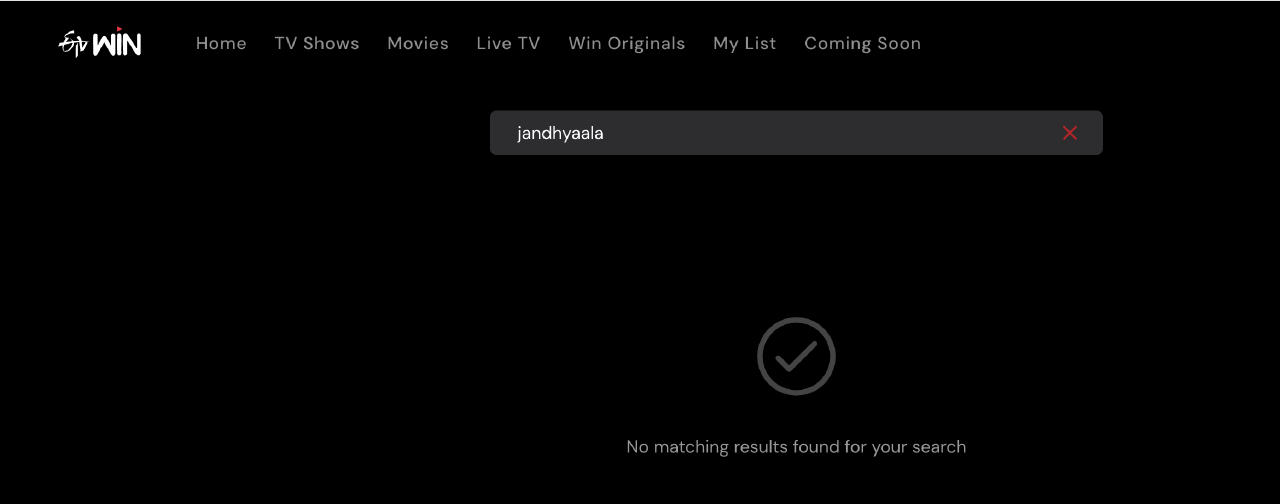
Armed with Claude Code, I decided to poke around a bit and see if there is a way to find what I was looking for. I trusted them to have designed a bad system and I was sure I could find a way around it. With a bit of poking around, I ended up downloading their entire catalog and building a local search engine for it.
Discovery
The site was a next.js app. Using chrome dev tools, and watching the network tab, quickly revealed their backend API at prodetvapi.etvwin.com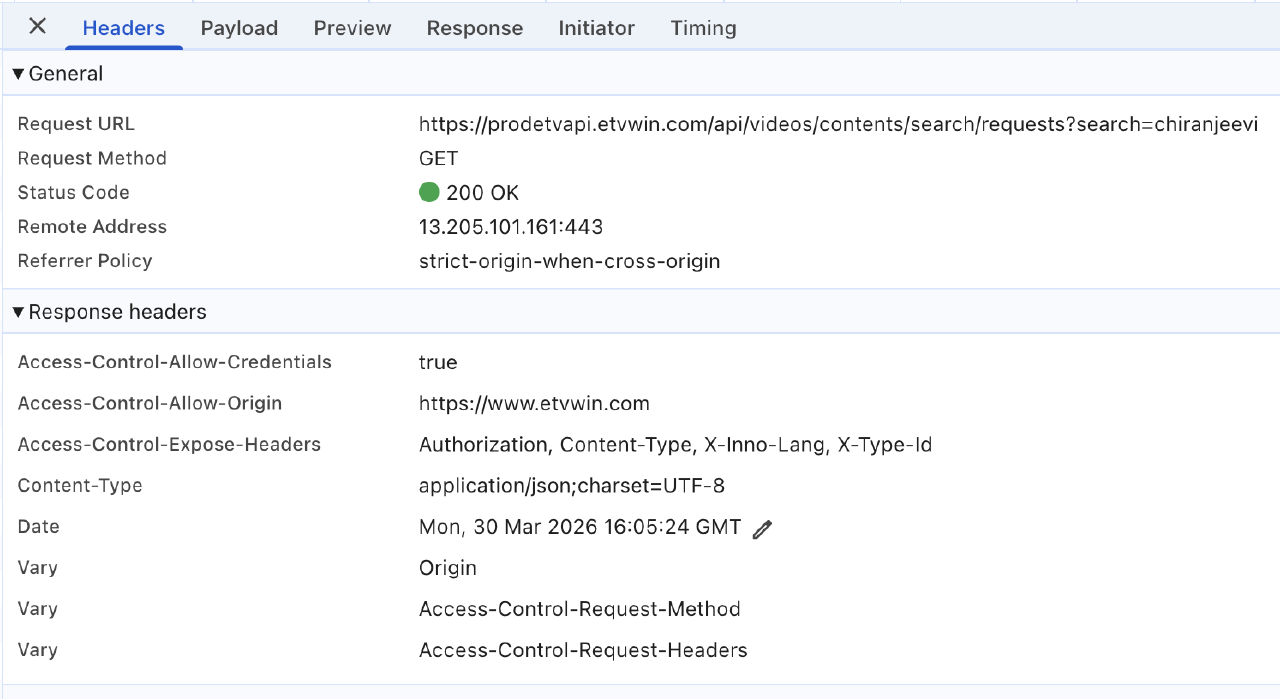
GET https://prodetvapi.etvwin.com/api/videos/contents/search?page={N}
Returns 30 items per page, paginated with sequential integers. No auth headers, no API keys, no session tokens. Total catalog: 626 items across 22 pages (497 movies, 129 series)
API Details
Each item comes back with 64 fields like
- Content metadata:
contentName,contentType,description,duration,ageRating - Business logic:
isPremium,isSvod,isTvod,isAvod,paywallAmount,paywallExpiry - Internal references:
contentId,customerId,countryId,categoryId,seriesId,seasonIdetc., including engagement data liketotalViews,watchedDuration. The frontend maybe uses 8 to 10 of these, the rest if just internal data leaking through. bad design.
Scraping
The next steps were relatively simple. A simple loop was all it took. I was able to extract all data in a few seconds.
let allItems = [];
let page = 1;
while (true) {
const res = await fetch(
`https://prodetvapi.etvwin.com/api/videos/contents/search?page=${page}`
);
const json = await res.json();
if (!json.data || json.data.length === 0) break;
allItems.push(...json.data);
page++;
if (json.data.length < 30) break;
}
// allItems now has 626 items with full metadata
There was no rate limiting, no CAPTCHA, no auth challenge all 23+ pages fetched in a few seconds.
Architecture Problems
No auth on catalog API
The endpoint https://prodetvapi.etvwin.com/api/videos/contents/search required zero credentials. The app doesn’t send any auth headers for browse or search requests. Even implementing a lightweight API key or a session token would have helped make it more secure. It doesn’t need to be a user level auth, even an app level token embedded in the JS bundle would have at least acted as a speedbump.
No field scoping
Every response dumps the full database row. Stream URLs (feed, customFeed), paywall configuration, internal IDs — none of this belongs in a public browse API. In fact, looking at the returned database row, I am pretty sure that their database backend is MongoDB. contentId values like 5ad47f4b1d3f723c21001870 are 24-character lowercase hex strings — that’s the exact format of a MongoDB ObjectId. The first 8 hex characters encode a Unix timestamp, and they decode to plausible dates that match the recent content episodes :)
So what could they have done better? A BFF (backend for frontend) pattern or field protection would have helped. The browse API should return: {contentId, contentName, thumbnail, genres, duration, isPremium}. Full metadata should only come from an authenticated detail endpoint like GET /api/content/{id} when a user actually clicks into a title.
Sequential Pagination
Another problem is, sequential pagination with no ceiling. When you design an API with page=1, page=2, ... page=22, things are predictable and parallelizable. Cursor based pagination with short-lived tokens would have helped here
{
"data": [...],
"nextCursor": "eyJsYXN0SWQiOiJhYmMxMjMiLCJleHAiOjE3MDk5...}"
}
Cursors should expire after 10+ mins and they should be single use. This helps prevent bookmarking the deep pages and forces sequential, realtime traversal, just like how a human would actually browse vs an agent or a scraping script.
No API surface separation
The same endpoint here serves both the public frontend and the internal admin needs. Fields like customerId, paywallExpiry, watchedDuration, and specialTagId are internal business data that leaked into the public response.
Maintaining separate API surfaces would have helped here.
- A public API: Limited fields, rate-limited, paginated with cursors
- An Internal admin API: Full fields, behind VPN/service mesh, authenticated with service tokens
The Irony
The whole reason I scraped this was because their frontend search really sucks! The other reason is because it is now so easy to do this, armed with tools like Claude Code - you just need to ask the right questions and understand what to look for. But, they had rich metadata - genres, languages, categories, durations, ratings, premium status - but their UI exposed almost nothing. If they had a half decent search, users wouldn’t go about poking. I think one of the API security features of a content catalog is a good product experience. If users can’t find what they are looking for from the UI, they will “get creative” with your API.
What I built from this
ETVWin is a regional OTT service, catering to a Telugu audience so the catalog itself is not huge. I asked Claude Code to build a self contained HTML app for a better search experience. The whole thing was 500 KB.
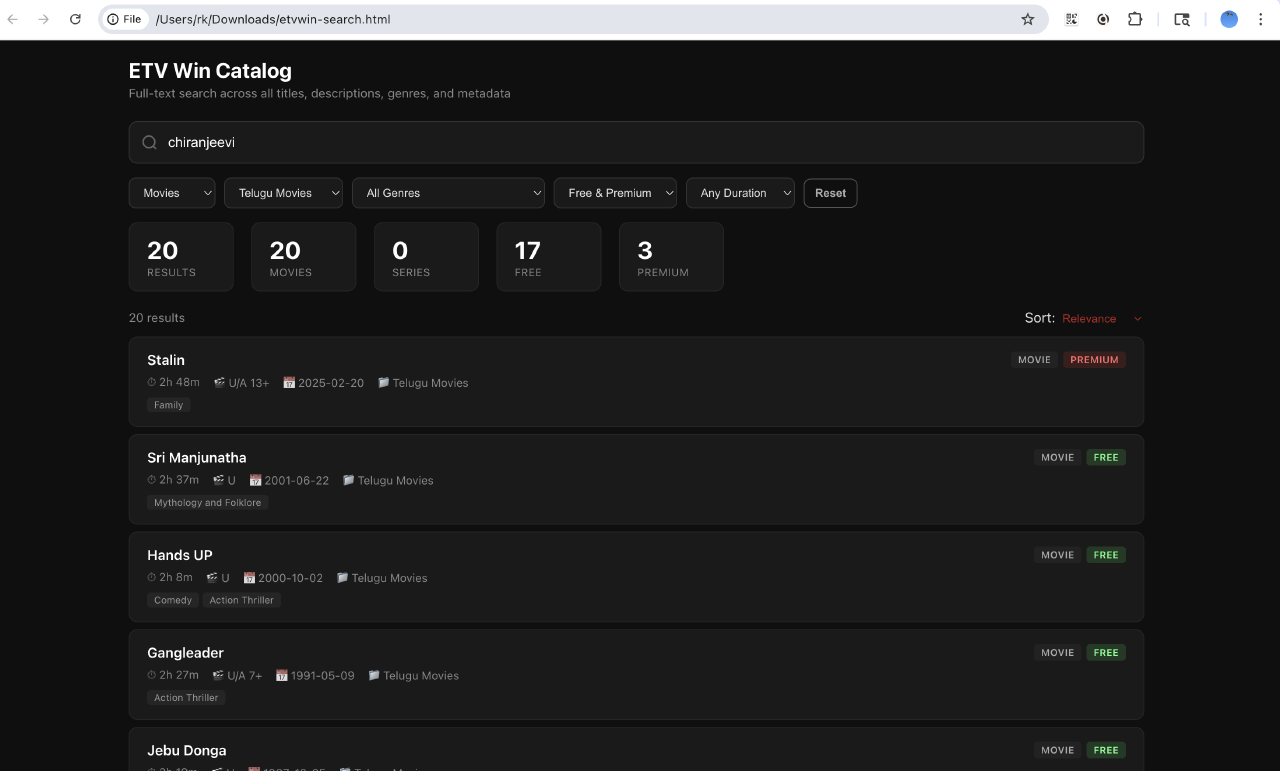
Profit!